
Understanding the Problem Through Mental Models
Introduction
The hardest problems in software are usually not the ones that look hard. Converting COBOL to Java looks straightforward; it’s just translation, right? But if you’ve ever tried to do it at scale, you know better. The real challenge isn’t syntax; it’s meaning.
This became clear when thinking seriously about legacy language translation systems. We’re not just moving code from one language to another. We’re preserving decades of accumulated business logic, maintaining the delicate relationships between signs and their meanings, and somehow teaching machines to understand what programmers really meant when they wrote those programs thirty years ago.
Most companies get this wrong. They treat it as a purely technical problem and wonder why their translations fail six months later when someone needs to modify the code. We need a different approach, one based on understanding how humans actually comprehend and work with legacy systems.
The Three Brains Insight
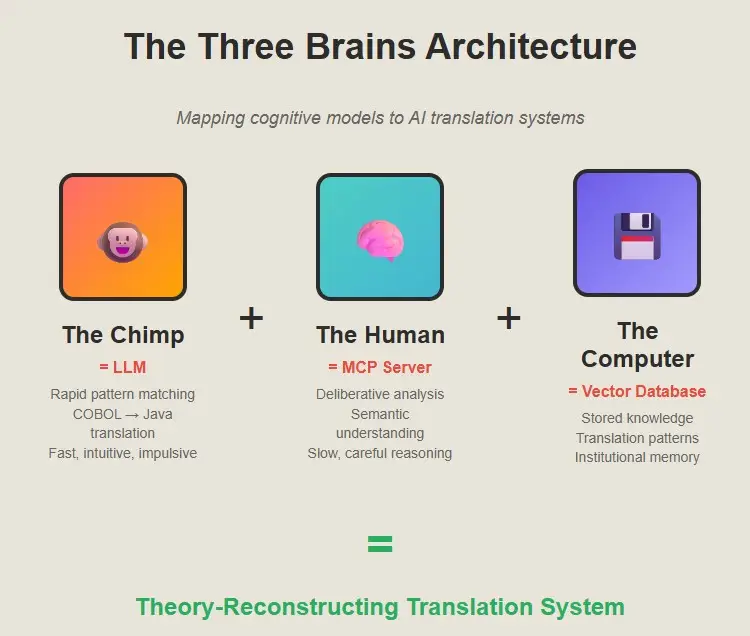
Steve Peters’ “Chimp Paradox” gave us a framework for thinking about this. Peters argues that we have three systems in our brain: the Chimp (fast, emotional, pattern-matching), the Human (slow, logical, values-based), and the Computer (stored knowledge and habits).
What’s fascinating is that AI translation systems naturally fall into this same pattern. And like humans, they only work well when all three systems are coordinated properly.
The Chimp: Fast Pattern Recognition
The Chimp is your LLM doing what LLMs do best, rapid pattern matching across enormous datasets. Show it a COBOL PERFORM statement and it instantly recognizes the pattern and generates a Java for-loop. Fast, intuitive, usually right.
When presented with COBOL or PL/I code fragments, the LLM’s “Chimp” excels at:
- Recognizing common programming constructs across languages
- Generating syntactically correct code quickly
- Maintaining consistent coding styles
- Handling straightforward translations where patterns are clear
But the Chimp is also impulsive. It sees MOVE A TO B and generates B = A without understanding that A might be a packed decimal field and B might be a character array, and the original programmer was relying on COBOL’s implicit conversion rules that don’t exist in Java. The Chimp translates the sign but loses the meaning. It might produce code that compiles but misses subtle business logic, creates security vulnerabilities, or generates non-idiomatic Java that defeats the purpose of modernization.
The Human: Deliberative Analysis and Reasoning
The Human is your Model Control Protocol (MCP) server—the part that actually parses the code, understands the data structures, and traces the flow of logic. It’s slow and deliberate. It reads the entire program, builds a semantic model, and figures out what the business logic actually does. It’s the part that knows the difference between what the code says and what the code means.
The MCP server acts as the thoughtful intermediary that:
- Parses legacy code with deep syntactic and semantic understanding
- Analyzes program structure, data flow, and business logic
- Identifies complex patterns that require careful translation
- Considers the broader context of the application architecture
- Makes deliberate decisions about how to handle ambiguous or complex constructs
- Builds control flow graphs and analyzes data dependencies
- Infers business rules from code patterns
This system doesn’t rush to generate code. Instead, it methodically breaks down the legacy program, understands its intent, and provides structured guidance about what needs to be translated and how.
The Computer: Stored Knowledge and Patterns
The Computer is your vector database full of patterns and successful translations. It’s institutional memory—the accumulated wisdom of thousands of previous translations, the knowledge of what works and what doesn’t.
This knowledge base serves as:
- A repository of proven translation patterns
- Documentation of common legacy-to-modern transformations
- Best practices for idiomatic Java generation
- Historical context about successful modernization approaches
- Semantic embeddings that help match legacy patterns to modern equivalents
- Domain-specific translation rules
- Anti-patterns to avoid
The vector database doesn’t think or reason—it simply provides relevant, contextual information when queried, much like how our stored memories inform our decision-making without conscious effort.
The Semiotics Breakthrough
Here’s where it gets really interesting. Programming languages are sign systems, and as any student of semiotics will tell you, signs are not their meanings. The same sequence of characters can mean completely different things in different contexts.
Consider this COBOL:
MOVE SPACES TO WS-RECORD
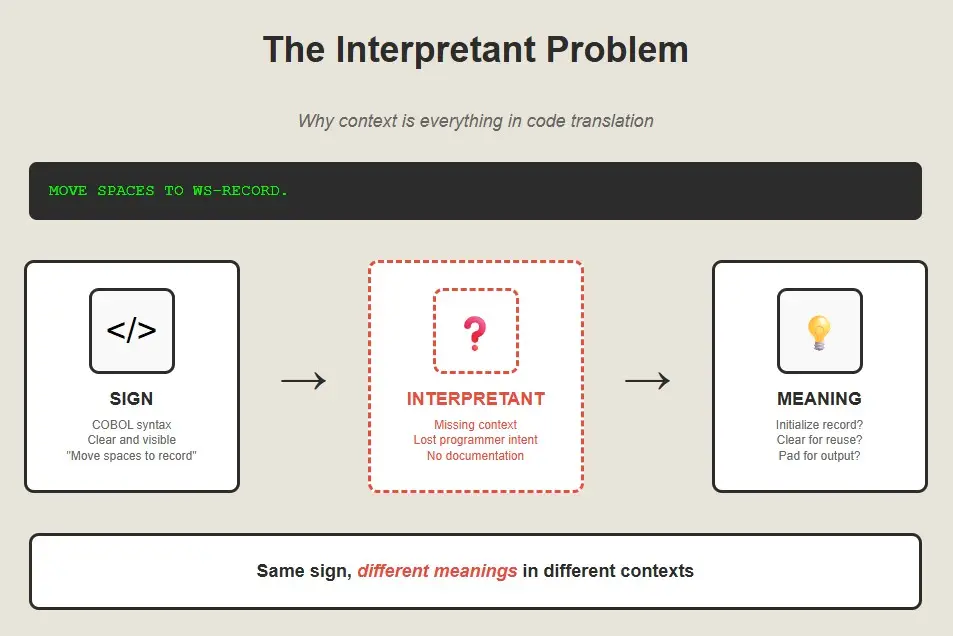
The sign is clear: move spaces to a work storage record. But what does it mean? It could mean “initialize this record,” or “clear this record for reuse,” or “pad this record with spaces for fixed-width output.” The meaning depends on the context that exists nowhere in the code itself.
This is what Charles Sanders Peirce called the “interpretant”—the thing that mediates between sign and meaning. In human communication, the interpretant is our shared understanding of context and convention. In legacy code translation, we have to build the interpretants into our systems.
The naive approach is to treat programming languages like natural languages and assume that translation is about mapping syntactic forms. But that’s missing the point. Programming languages are theory-laden in ways that natural languages aren’t.
Signs, Meaning, and Context
The key insight from semiotics is that meaning is always contextual. The same COBOL construct can mean different things in different domains, different decades, and different companies.
A vector database needs to encode not just syntactic patterns but semantic contexts. A COMPUTE statement in a financial system means something different from a COMPUTE statement in a manufacturing system. The signs are the same; the meanings are different.
This is why simple rule-based translation systems fail. They treat signs as if they have fixed meanings. But meaning is relational—it depends on the entire web of relationships between signs, interpretants, and contexts.
Programming as Theory Building
Peter Naur figured this out in the 1980s. In his essay “Programming as Theory Building,” he argued that programs aren’t just instructions for computers—they’re theories about how to solve problems. The real program isn’t the code; it’s the theory in the programmer’s head.
This insight is devastating for legacy translation. When you’re converting COBOL to Java, you’re not just translating code. You’re trying to reconstruct the theory that guided the original programmer’s decisions. And that theory exists nowhere in the code itself.
Why did the programmer choose to use a binary search here instead of a linear search? Why is this field defined as PIC 9(5) instead of PIC 9(4)? Why does this validation routine check for spaces before checking for zeros? The answers are in the theory, not the code.

Most of the theory is lost. The original programmers are retired or dead. The documentation is missing or misleading. The business requirements have changed. You’re left with code that works, but nobody knows why.
The Deeper Pattern
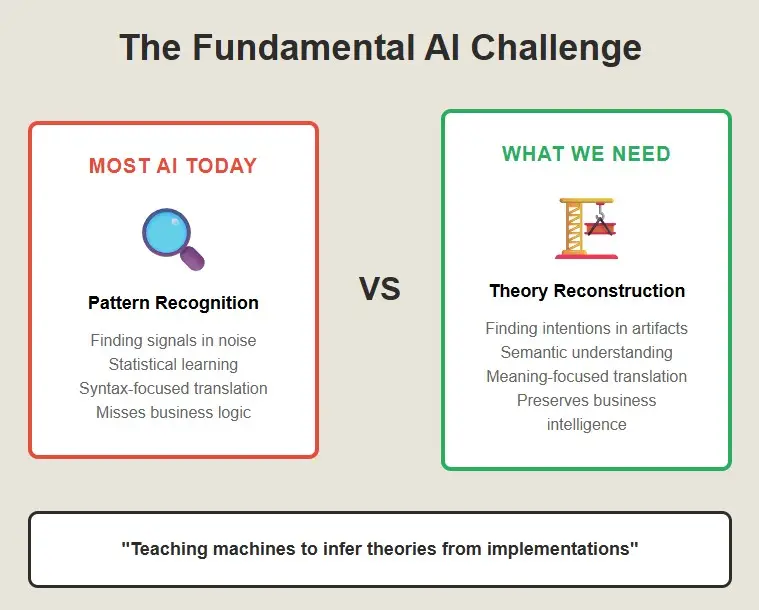
What’s really happening here is that we need to teach machines to do what humans do when they read code—we need to teach them to infer theories from implementations. This is a fundamentally different kind of AI problem than most of what the industry works on.
Most AI is about pattern recognition—finding signals in noise. But theory reconstruction is about meaning-making—finding intentions in artifacts. It requires not just statistical learning but semantic understanding.
The three-system approach works because it mirrors how humans actually understand code. We use fast pattern recognition (Chimp) to get oriented, careful analysis (Human) to understand the logic, and accumulated experience (Computer) to infer the intentions.
Why This Matters
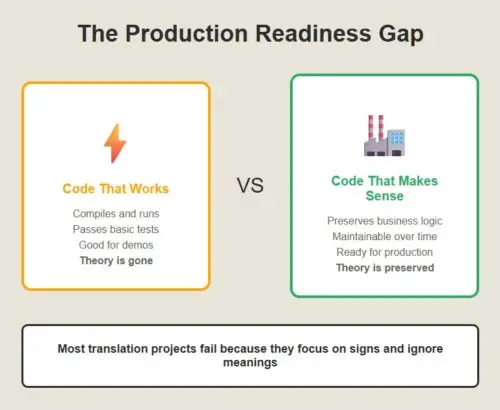
The difference between syntactic translation and semantic translation is the difference between code that works and code that makes sense. Code that works is good enough for a demo. Code that makes sense is good enough for production.
Most legacy translation projects fail because they focus on the signs and ignore the meanings. They generate Java that compiles and runs, but doesn’t capture the business logic. Six months later, when someone needs to modify the code, they discover that the theory is gone.
The real lesson here isn’t about COBOL or Java. It’s about the relationship between signs and meanings, between code and theories, between what programs say and what they mean. Once you understand that, translation becomes a different kind of problem entirely.
A more interesting one.